Text Export settings
This module enables you to export data from your database into text, XML and JSON files.
This module enables you to export data from your database into text, XML and JSON files. This data can then be imported into other software, Office applications, websites or databases.
If the Import & Export Panel is not visible, make it visible by pressing F9,X or via the View menu in the main menu bar.
The output generated by this export module is constructed from fields. One or more fields form a record. For each exported file one record is written to the output file. For non-XML formats, fields are separated by a freely selectable field separator and records are separated by a record delimiter. XML uses a fixed structure and wraps each field and record in an XML tag as described below.
Here is an example of a typical output file. The file has three fields per record (file name, datetime, size in bytes) and there are three records in total. The fields are separated with a comma (,) and the records with a carriage return / line feed.
c:\images\2012\_DSC126121.jpg,2012-01-03 12:00:00,1234568 c:\images\2012\_DSC126321.jpg,2012-01-05 12:00:00,1254500 c:\images\2012\_DSC129569.jpg,2012-01-16 12:00:00,1301192
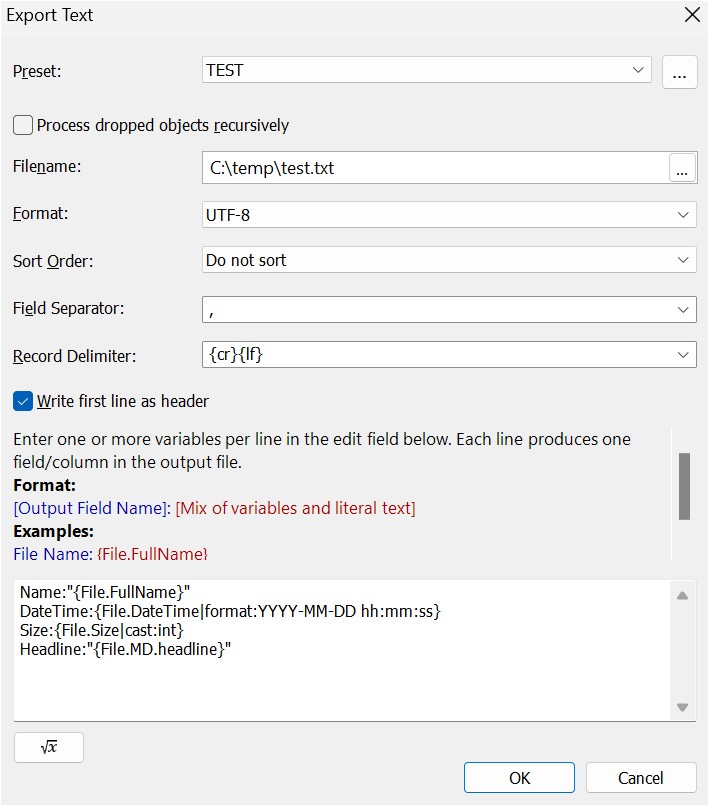
The module displays a dialog box that allows you to specify the format and contents of the output file. The settings you make here depend on the purpose of the resulting file or which application you plan to use to process the output.
Text Export settings
| Preset | Select a preset from the list or use the last used settings. You can also access the Preset Manager via the ... button. | ||||||
| Process dropped objects recursively | Depending on what you have dropped on the filter, this option either includes child folders or child categories. If you have dropped files, the option has no meaning. | ||||||
| Filename | Name and folder of the output file | ||||||
| Format | The file format to use for the export. Currently UTF-8, Unicode (UTF-16) and XML are supported. The default format is UTF-8 which makes the exported files compatible with a wide range of applications and operating systems. | ||||||
| Sort Order | This list contains all sort profiles defined for your database. Choose one of the profiles to control the sort order of the exported files. If you use custom sort orders in your File Windows and you want to export the files in the same order, select all files via Ctrl+A and then drag and drop this selection onto the Text Export filter. Select the 'No Sort' profile in this case. | ||||||
| Field Separator | For non-XML-based formats. The character(s) you enter here are used to separate the fields in the output. You can use any character or combination of characters, or use one of the following special tags:
Make sure to choose a field separator that is not part of the data you write to the file. | ||||||
| Record Delimiter | For non-XML-based formats. The character(s) you enter here are used to separate records in the output. You can use any character or combination of characters. Or use one of the following special tags:
Make sure to choose a record delimiter that is not part of the data you write to the file. Windows text files usually use a carriage return / linefeed so you may want to specify {cr}{lf} as the record delimiter. If you are targeting UNIX/Linux systems, use only {lf}. | ||||||
| Write first line as header | For non-XML-based formats: Set this option to write a first line with the field names into the output file. For all formats: The field names will be generic names like F1, F2, ... Fn unless you specify field names in the field specification. |
The Text Export module uses a flexible approach to specify which information to export. In the edit field at the bottom of the dialog box you can enter a free mix of IMatch Variables and literal text.
The general format is:
Variables and literal text for field 1 Variables and literal text for field 2 ...
or
Field Name:Variables and literal text for field 1 Field Name:Variables and literal text for field 2 ...
The optional Field Name: is the name of the field in the output file if you use the Emit first line as header option or XML output. The text after the colon specifies the contents of the field. You can freely mix variables with literal text and you can use more than one variable per field.
Make sure you use only valid field names for the output format and the application you want to import the file into.
For example, many applications don't allow blanks (spaces) in field names, and XML/JSON definitely do not allow blanks in field names. Use the underscore _ as a safe replacement; for example, instead of File Name use File_Name.
{File.FullName}The output file has one field (column) per record. The field is the fully qualified file name. If you use XML or emit a header line, the field will be named F1.
c:\images\beach.jpg c:\images\flower.jpg ...
and with headers it will be:
F1 c:\images\beach.jpg c:\images\flower.jpg ...
This example uses a field name to explicitly name the output field:
Dateiname: {File.FullName}The output file has one field per record. The field is the fully qualified file name. If you use XML or emit a header line, the field will be named Dateiname.
Dateiname c:\images\beach.jpg c:\images\flower.jpg ...
This example uses three rows with variables and field names:
FileName: "{File.FullName}"; DateTime: {File.Modified|format:YYYY.MM.DD hh:mm:ss} Size: {File.Size|cast:int} Bytes
The output file has three fields per record: Fully qualified file name, date and time of last modification and the size of the file in bytes. The fields are named FileName, DateTime and Size. A custom datetime format is used and the file size is emitted as an integer number without any additional formatting, but with the word Bytes appended.
The output for this field specification will look like this (assuming you use the first line as a header and a comma as the field separator):
Filename,DateTime,Size "c:\images\1.jpg",2011.05.02 12:00:01,163739 Bytes "c:\images\22342.jpg",2011.05.02 12:01:05,1462928 Bytes
Note how the " characters around {File.FullName} in the field specification are copied literally to the output file.
Some applications require text values to be wrapped in ", which can be easily achieved by adding " around each text variable in the field specification.
If you use XML as the output format, the result will look like this:
<?xml version="1.0" encoding="utf-8" ?> <photools.com-imatch xmlns:ptrm='http://schemas.photools.com/textexport.xsd' vendor='photools.com' version='1.0'> <filerec> <Filename>c:\images\1.jpg</Filename> <DateTime>2011.05.02 12:00:01</DateTime> <Size>163739 Bytes</Size> </filerec> <filerec> <Filename>c:\images\22342.jpg</Filename> <DateTime>2011.05.02 12:01:05</DateTime> <Size>1462928 Bytes</Size> </filerec> </photools.com-imatch>
Some applications expect you to quote text columns (and sometimes all data), especially in CSV files. Quoting means to include column data into " or other characters. To use quotes in the generated text file, just add them to your field specification.
Note the " added in front and behind each field:
FileName: "{File.FullName}"; DateTime: "{File.Modified|format:YYYY.MM.DD hh:mm:ss}" Size: "{File.Size|cast:int} Bytes"