The CSV Import user interface
This script-based import module enables you to import data from CSV (comma-separated value) files into metadata or Attributes.
This script-based import module enables you to import data from CSV (comma-separated value) files into metadata or Attributes. CSV files can be created by many applications, e.g. Microsoft Excel or Access, database applications, back-office systems and IMatch.
If the Import & Export Panel is not visible, make it visible by pressing F9,X or via the View menu in the main menu bar.
This import module is implemented as an IMatch App. The source code can be found in the system app folder.
CSV is a common text file format. Many applications are able to output data into this format, e.g. Microsoft Excel and Access, other Office products, database and financial applications, IMatch itself (via the Text Export Module) and many others. Several variants of CSV exist and this import module tries to support most of the common varieties.
A CSV file contains any number of rows (records). Each record consists of one or more columns. Often the first row in the file contains the column names and must be skipped when importing data. The delimiter characters used to separate rows and columns vary between applications, operating systems and languages. IMatch allows you to configure these delimiters in the user interface of this import module.
Here is a sample CSV file with three rows. Each row has four columns. The first row contains the column names. The first column is the file name column.
The file uses ; as the column delimiter and the Windows standard CRLF (carriage return / line feed) to separate the rows. Each value is quoted in "" to allow the use of the column delimiter ; as part of the column value:
"File Name";"Case Number";"Comment";"Notes" "c:\images\2014\05\_DSC1290.raw";"123819";"This is a comment";"Place for more notes" "c:\images\2014\05\_DSC1291.raw";"123819";"Comment for file 1291";""
This is the standard format emitted by many standard applications running on Microsoft Windows.
Before you attempt to import CSV data into IMatch, open the file in Windows Notepad or another text editor. This allows you to see how the file is structured, which column delimiter is used and if the first row contains the column names. Sometimes applications use a comma as the column delimiter or a tab. If the file has been created on UNIX/Linux platforms, the row delimiter is usually a single line feed (LF) instead of the Windows standard CRLF. You need to configure the import to match your file format.
It is a good idea to make a backup of your database before running an import.
In case something goes wrong or the results are not as expected, you can just replace the database with the backup. This is often much easier than removing imported data by hand.
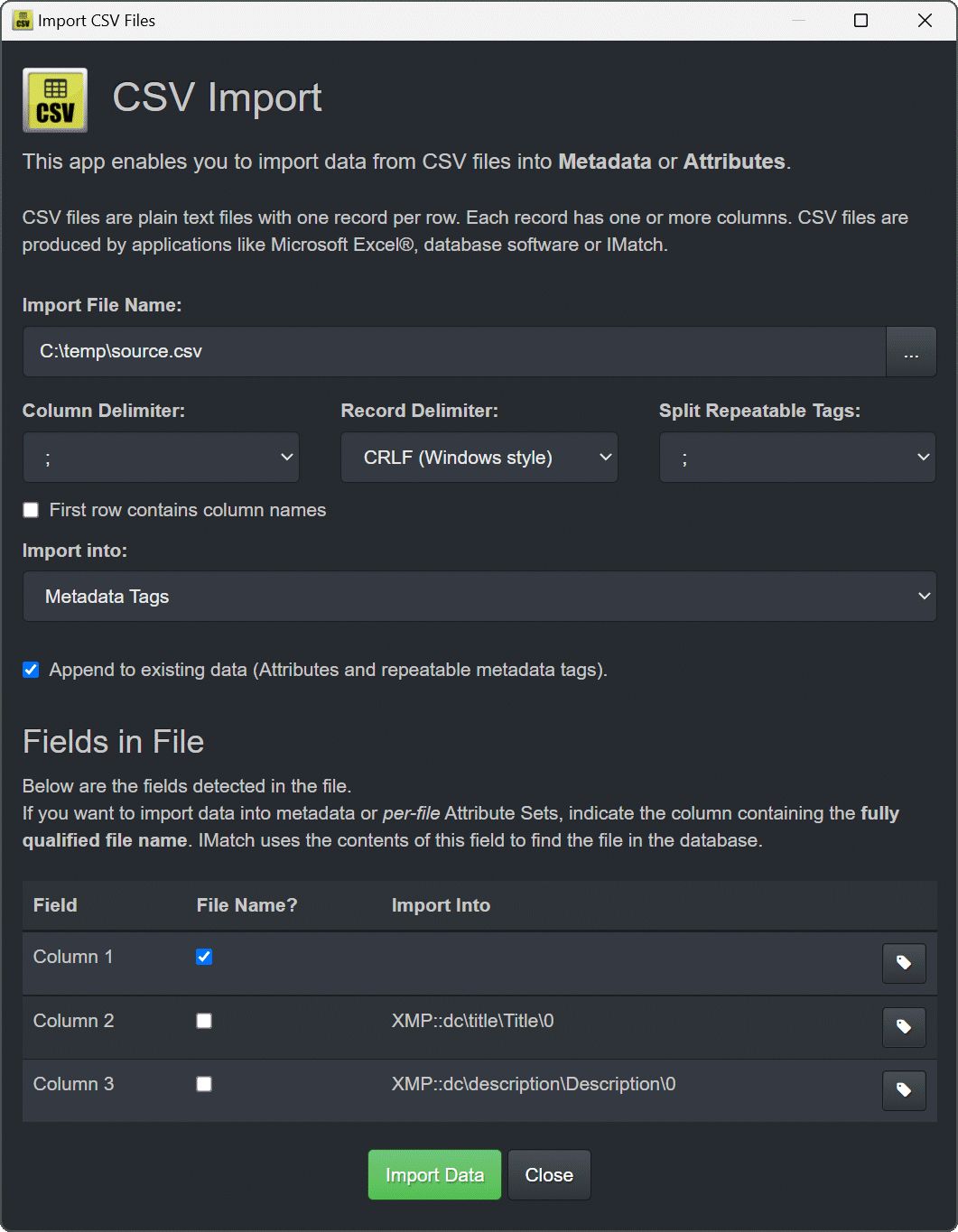
Run the import module from the Import & Export Panel. The user interface opens after a few seconds:
The CSV Import user interface
Set the field delimiter and record delimiter to match the file you want to import. Then use the Browse (...) button to select the CSV file to process. The import module then loads the file and analyzes it. After a few seconds the dialog box displays the columns found in the file.
With the Import into option you configure where the imported data goes. You can import data into global Attribute sets, per-file Attribute Sets and Metadata tags. Leave the target column empty if you don't want to import a specific column available in the input file. Depending on whether you have chosen an Attribute Set to import or Metadata tags, the column table allows you to select the target attribute or metadata tag.
File names must not contain the ~ character. If you really must use ~ in file names, escape them as ~~ in the CSV file.
When you import into Attributes, the imported data is added to existing attribute data already in the IMatch database.
If you want to replace attribute data, delete the existing data via the Attribute panel before you run the import.
If you want to import data into per-file Attribute Sets or Metadata tags, IMatch has to be able to find the file. The column you indicate as the file name column (via the radio button in the column table) will be used to locate the corresponding file in the database.
IMatch ignores data in the CSV file for which it cannot find a matching file.
If you import data into repeatable tags like hierarchicalSubject (keywords), you can either replace the existing data in the tag, or append new data to it. This is controlled via the Repeatable tags option. If you choose a setting different from Don't split, the data in the corresponding column is appended to the elements already in the tag. If the chosen split character appears within the column data, the column data is split and then each resulting element is appended to the repeatable tag.
Consider a column containing these keywords in this form:
beach;summer;vacation;usa;family
If you import data into Metadata tags, you will most likely choose the hierarchicalSubject tag (hierarchical keywords) as the target. If you now set the Repeatable tags option to ; the CSV import module splits this text into the five individual keywords and appends them to the keywords already in the target file.
If the target tag is not repeatable, the Repeatable tags option has no effect. If you want to replace existing keywords, delete them in the Keyword panel before running the import.