Data-driven categories use metadata and variables to automatically organize your files by things like camera model, lens, photographer, country, location,...
Data-driven categories use metadata and variables to automatically organize your files by things like camera model, lens, photographer, country, location, people shown, band, author, ...
You may know similar concepts from other software under names like Smart Collections or Intelligent Collections.
But IMatch data-driven categories go way beyond what you may have used in other software.
The unique data-driven category concept of IMatch enables you to categorize your files automatically based on metadata, IMatch Attributes and Variables. Common uses for data-driven categories are:
When you set up a data-driven category for a metadata field (tag), IMatch looks at all the different values stored for this tag in your database. For each unique value found, IMatch creates a child category under the data-driven category and assigns the files with that value to this category.
Data-driven categories are, by default, dynamic. If you add or remove files or you change metadata, all you need to do is refresh the data-driven category to make it represent the current contents of your database.
Consider that you manage an image collection with images taken with a wide variety of cameras from different vendors. You want to set up a category hierarchy with one category for each brand, something like this:
Brand and Model |-- Canon |-- Nikon ...
If you set up a data-driven category for this, IMatch does the following:
IMatch supports data-driven categories with up to 6 levels, which offer you a great deal of flexibility. A multi-level data-driven category is based on two or more different metadata values. Each value produces one level in the resulting category hierarchy.
Extending our example from above by including a second level, with the camera models used:
Brand and Model |-- Canon |-- Model 1 |-- Model 2 |-- Nikon |-- Model 1 |-- Model 2 |-- Model 3 ...
If you set up a data-driven category for this, IMatch does the following:
Another example would be a category hierarchy for your MP3 music collection. At the top level you could use the Artist tag, below that the Album tag and below that the Title tag. The resulting category hierarchy gives you direct access to each MP3 file by artist, album and track title.
Or, if you fill out the XMP metadata Country, City and Location tags for your files, you can set up a data-driven category with country on level one, and below that the cities for each country and below that the locations within each city.
For this example, we create a data-driven category for camera make and camera model. The resulting category hierarchy will have two levels.
Start by creating a new category and give it a meaningful name. For our example, we add the category directly below @All and name it Make and Model.
Right-click on the category to open the context menu and select the Data-driven Properties command.
Alternatively click on the ... button behind the Data-driven property in the properties panel for the category.
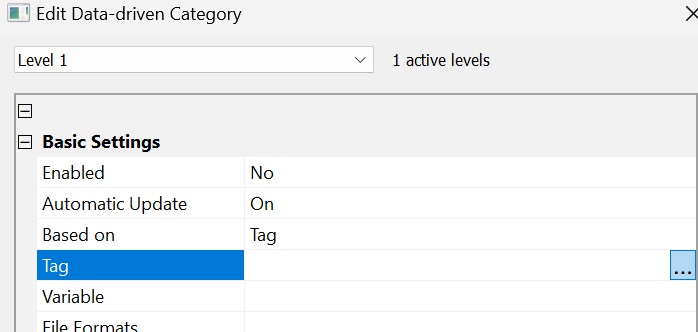
In the Edit Data-driven Category dialog box, click on the row labeled Tag and click the ... button to open the Tag Selector dialog box box.
We use the Make tag from the Standard tab for this example:
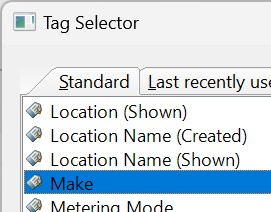
You can use any metadata tag when creating a data-driven category. If the tag is not in the list of frequently used standard tags, use the search function in the Tag Selector dialog box box to find the tag.
Double-click on this tag to add it to the result list and close the Tag Selector with OK. The selected tag will be inserted in the Tag row of the data-driven category dialog box:
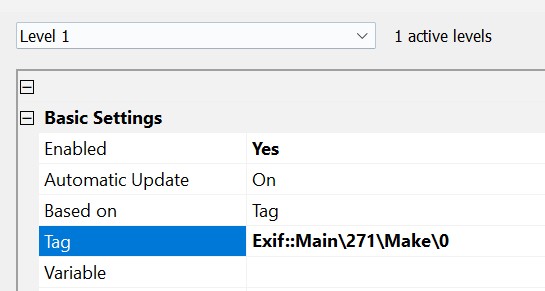
Make sure the Enabled option is set to Yes to make this level active. Tip: category properties modified show in bold.
The OK and Preview buttons will become available when at least one level is enabled.
This is all you have to do to define the first level of your data-driven category.
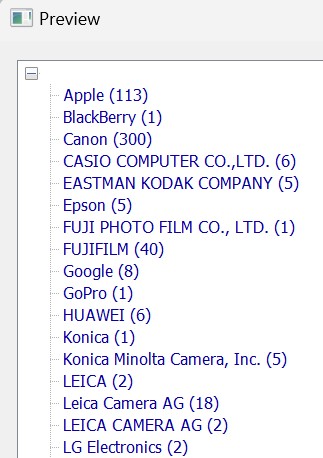
To see the results of this level, click the Preview... button. This opens a new window that retrieves the data from the database and outlines it in a tree control. This is a great way to check the results and the settings you have made.
You should see one entry for each unique camera maker/vendor recorded in the EXIF Make tag in your images.
Note that camera companies sometimes use different maker names. See, for example, the entries for Leica in the screenshot below. Luckily, data-driven categories in IMatch offer features to deal with that (the Replace Mask option).
The database used for this example contains many sample images produced by different camera models from many vendors. Your results will be different.
Close the Preview dialog box to return to the Data-driven Category editor.
Data-driven categories support up to six levels. You can select the level you want to configure via the Level drop-down control at the top of the dialog box. A level is only used for the data-driven category if you set the Enabled property to Yes. This property is the first in the property grid.
You can temporarily disable a level by setting the Enabled property to false. The level retains its settings so you can re-enable it later at any time.
There must always be at least one enabled level. You cannot close the dialog box with OK when all levels are disabled.
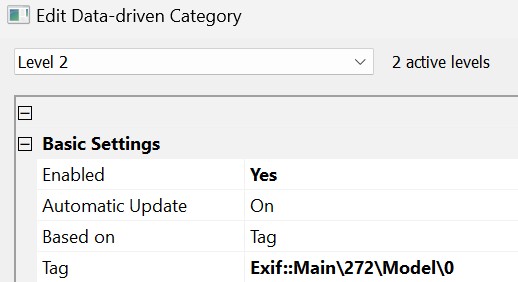
In the Level drop-down control at the top of the dialog box, switch to Level 2 and select the Model tag via the Tag Selector dialog box.
To see the result of the settings so far, click on the Preview... button again. The result for our sample database looks like this:
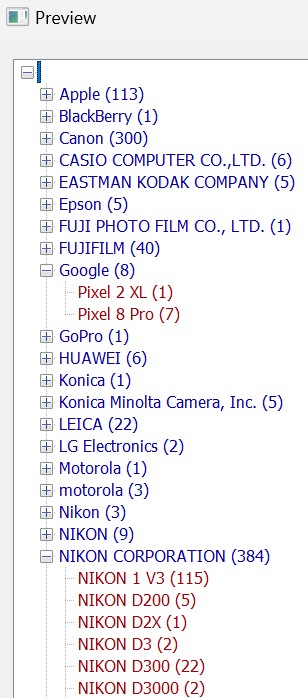
Your results will be different. Maybe you see only one or two vendors/camera models. Our sample database contains images from many photographers using different types of equipment and almost two decades worth of images.
If your database contains many files, generating the preview may take a few seconds.
You can close the Preview dialog box at any time via the Close button even if IMatch is still loading and processing data.
The data-driven category is now complete. Click OK to close the Data-driven Category editor.
IMatch now stores the data-driven definition in the category Make and Model and then performs the database operations to produce the actual category hierarchy. Depending on the size of your database and the performance of your computer, this may take a few seconds. When the operation has completed, the data-driven category and all the new child categories created below it become visible in the Category View. It should look similar to this:

The Make and Model category has two levels of child categories, one for each level in the data-driven definition you've just created.
Performance Tip:
IMatch has to update categories visible in the Category View or the Category Panel often. This may reduce performance if you create many complex data-driven categories.
Create all your data-driven categories under a common parent category. You can then collapse the parent category, hiding all data-driven categories to avoid unnecessary updates.
When you create a database, IMatch automatically adds a set of useful data-driven categories. The categories are named IMatch Standard Categories and IMatch Workflow Categories:
This category hierarchy (all categories are data-driven) organizes images and other files by things like Aperture, Lens, Camera Name, Location, and Make and Model.
You can use these categories as they are created, customize them to your needs, or delete them when you don't need them and don't want IMatch to spend time updating them.
The categories in this hierarchy mostly use category formulas to analyze your database and produce categories like "No Description", "No Keywords" or "Unrated Files".
Like with the standard category set, use these categories in any way you like. Study the formulas used to get ideas for categories you might want to create for yourself. Delete categories you don't need.
The special Other element is important when you work with incomplete or partially missing metadata.
Back to our sample Make and Model category. What happens if an image has no make or model? Where do these files show up in the data-driven category?
You may want to enable the Other element on this or the first level to handle files without Make or Model information. The Other element will gather these files and assign them to a child category named 'Other' (or any name you choose). See the information on the Other property below for details. Other is basically a bucket that collects all files without a Make.
You should enable Other when you expect that not all files have a value on that level and you want to include these files in the data-driven category. If there is no Other, files without a value will not be included in the category. If you have 1000 image files, but only 200 have an entry in Make, the data-driven category will show only 200 files, unless you use Other to collect all files without a Make. Which may be useful, or not.
Consider the following example: You set up a data-driven category with three levels:
Country
City
LocationIMatch retrieves the country, city and location metadata tag for each file in the database and assigns the files to their respective categories. To do this, it starts at the lowest level (Location) and works its way upwards to the Country level. A file with the values County:USA, City:Daytona, Location:Beach can be mapped easily:
USA
Daytona
BeachBut what happens for a file which has no location value? Consider a file with Country:UK, City:London but no Location. IMatch cannot create a node on the Location level for this file because it has no location. This file will thus not be included in the data-driven category!
But if you enable Other for the location level, IMatch puts the file into that category. From there it can again go up to the next higher level (City) and from that to Country. The file will thus end up in
UK
London
OtherThis Other element 'collects' all files without a value on the Location level. And then these files will be rolled up to the top-level based on their City and Country values. If a file has no value for City, it will be assigned to the 'Other' element on the City level and so on, up to the top level.
The general rule is:
If you expect that some of your files have no value for one of the levels in your data-driven category, enable the option to use an 'Other' element. Unless you want to explicitly suppress these files.
When you make changes to your database, the contents of data-driven categories may become pending. This means they may no longer reflect the actual contents of your database and needs to be refreshed. Pending data-driven categories use a special icon:
A stale data-driven category
To refresh the category, select the category and press Shift+F5 or choose Refresh Data from the context menu. To refresh all data-driven categories at once press Shift+Ctrl+F5 or use the corresponding command from the context menu of any data-driven category.
Data-driven categories may need to process a massive amount of data. Consider a database with 100,000 files. To find all files for a given camera Make, IMatch needs to load the metadata for 100,000 files, look at each Make value, create a list of all unique values for Make (Nikon, Canon, Sony, Panasonic, ...) and which files have that value. Then it has to repeat all that for the camera Model level. That's a lot of data to move around.
Especially for large databases with hundreds of thousands of files, reducing the number of files used for a data-driven category can be a real performance boost.
Often you can reduce the number of files to process by restricting the category to a certain file format (or several). For example, when you create a data-driven category that uses MP3 tags like Artist and Album, you can reduce the files to process by setting the file formats filter to include only files with the .mp3 extension:
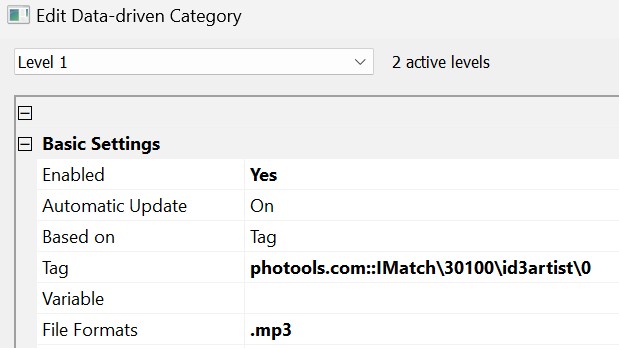
Limiting a data-driven category to selected file formats.
If you use this filter, IMatch calculates the contents of the level like for all other data-driven categories, but considers only files matching one of the given file extensions. This is very useful if you only want to analyze certain files, e.g. PDF documents, MP3 files, or images taken with a certain camera.
If you create data-driven categories that analyze specific maker note tags or other metadata that exists only in specific files (e.g. your RAW files), use the file formats filter to restrict the category only to files in that format.
Even more useful is the Category Filter. It allows you to limit the data-driven categories to files assigned to one or more other categories. For example, you may want to create a data-driven category based on the Title tag, but only for files assigned to your Family category or its children. This gives you a data-driven category that groups your images based on Title, but only includes family photos.
Another typical example would be to limit a data-driven category to files with one or more specific keywords. Or to files created for a customer. Or files in one or more motive categories...
The Category Filter takes the names/paths of one or more regular expressions, separated by a semicolon. The supported syntax is the same as used in @Category formulas, which gives you a great deal of flexibility and control. For example:
@All|Family
All files in the Family category and its children.
Claudia
All files from all categories containing the word 'Claudia'.
If you use more than one category in this filter (or your filter matches more than one category), the files in these categories are combined with the Boolean OR operator. This means that the result is all files, combined.
See the description of the @Category formula for more information about regular expressions and how to address specific categories in your category hierarchy.
When you switch the Based on property from Tag to Variable, you can enter a variable expression into the Variables property.
See Variables for information about IMatch variables.
Using variables as the basis for data-driven categories gives you an extra set of tools to work with. For example, you can create data-driven categories based on IMatch Attributes, or using data not directly accessible via metadata tags.
A word of caution: Data-driven categories based on variables can be very slow to process. IMatch can create metadata-based data-driven categories very efficiently on the database level. Parsing variables is a much more complex process and thus much slower. Variable-based data-driven categories may be 10-100 times slower than normal data-driven categories.
You may want to switch automatic updates off for variable-based categories. And maybe use a File Format filter or Category Filter to reduce the number of files to process.
Despite the performance penalty, variable-based data-driven categories may be useful to solve specific problems. You can create data-driven categories based on Attributes, for example. Or combine the values of multiple metadata tags to form the expression used to calculate the data-driven category. Sometimes using a variable together with one or more formatting functions is what you need to automatically group your files.
If you switch automatic updates off for data-driven categories you seldom need, they don't affect the performance of IMatch at all.
In the Attributes help topic we use an Attribute Set for tracking submissions (of images to photo agencies). Each image that has been submitted to one or more agencies has an attribute record with the information about the site, the date and some other data.
To create a data-driven category that shows us the files submitted to each site, we use the variable corresponding to the Site Attribute:
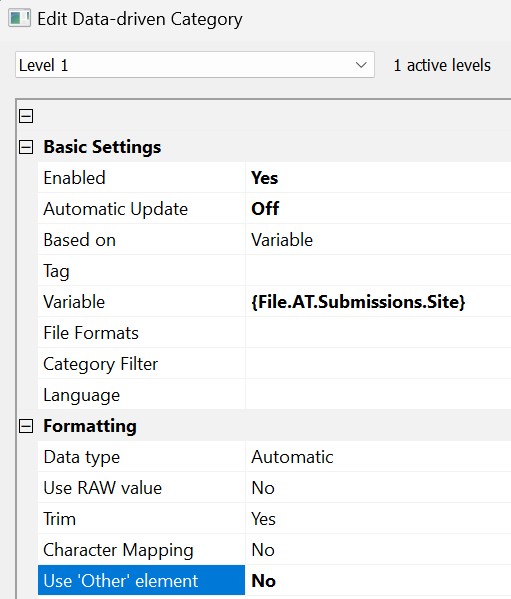
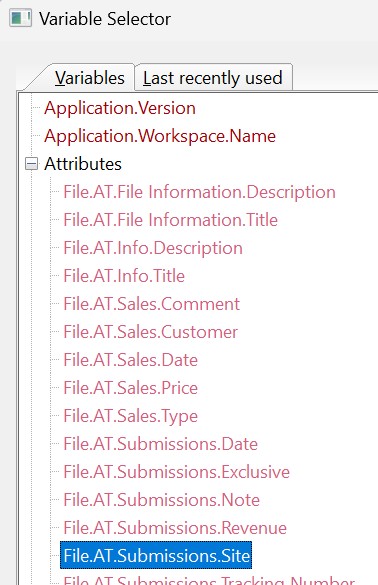
We switch the Automatic Update option to Off. This category is no longer updated automatically in the background.
This is a good idea for data-driven categories you only use occasionally. Refresh it only when it's needed, which conserves energy and keeps your database performing well.
When needed, select the category in the Category View and press Shift+F5 to update it.
For this category, we switch 'Other' off since we are not interested in files without Submission attribute records.
After refreshing the category manually, we get this result for our sample database:
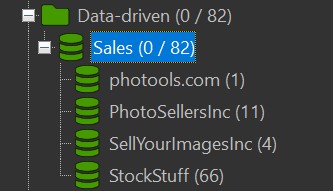
For each client used in our Attributes, IMatch has created a matching category, with all files submitted to that client. Cool. We can now see immediately which files have been submitted, and to which of our clients.
Data-driven categories support variable expressions consisting of multiple variables, free text, and all variable formatting functions available in IMatch. See the Variables help topic for more information.
Use the VarToy app to try out your variable expressions.
You can configure the data-driven category via the Properties panel in the Category View like other categories. Some properties are not available for data-driven categories, e.g., you cannot set a formula.
Child categories of a data-driven category inherit the color settings of their parent category. If you color the data-driven category, all dynamically created child categories will use this color too by default.
Some characters are reserved and cannot be used in category names. This includes the | and @ characters. When creating category names from data values IMatch automatically replaces unsupported characters with an underscore.
Use the Replace Mask feature to replace invalid characters with a character of your liking. You can also use this feature to provide more easily understood names in place of abbreviated names, e.g., 'Motorola' instead of 'MB885'.
So far we have covered the most basic features of data-driven categories. These are already sufficient for many cases. But there is much more to discover. Read on.
IMatch data-driven categories support a range of advanced features for data processing, transformation, and cleanup. These features can be configured via the Data-driven Category Editor. Expand all property groups in the grid to see all available features and settings.
Chances are that you'll never need many of the advanced features explained below.
But if you have to deal with mixed quality metadata or your files come from different sources, you'll find that the cleanup and filter functions are indispensable.
| Basic Settings | |
|---|---|
Enabled | If this is set to Yes, the level is enabled and participates in the data-driven category generation. You must have at least one enabled level in your data-driven category. |
Automatic Update | If this is On, the category is kept up-to-date automatically. IMatch refreshes it in the background when needed, during idle time. Categories are only refreshed in the background when the corresponding option is on in Edit > Preferences > Background Processing. If this is Off, you need to manually refresh the category using Shift+F5 or the corresponding command from the context menu. The properties panel in the Category View displays the status of this option. This way you can always tell if a data-driven category is automatically updated or not. |
Based on | This option controls whether the category is based on a Metadata Tag or a Variable. |
Tag | The metadata tag that is used to fill the category level. To retrieve the data for the category, IMatch looks at all unique (distinct) values for that tag in the database. Some metadata fields can have thousands or even tens of thousands (!) of different values. |
Variable | Enter the variable expression to use for this category. See Data-driven Categories Based on Variables above for more info. |
File Formats | This option enables you to restrict the contents of the data-driven category to files in selected formats. By default, data-driven categories use all files in the database as input. To limit the input to one or more file formats, specify the extensions of these file formats, separated by ; For example, using .mp3 in this field limits the data-driven category to MP3 files only. With .jpg;.tif the data-driven category considers only JPEG and TIFF files. You can use this feature if you are creating data-driven categories using metadata only available for certain formats. For instance, when you use metadata tags like MP3 artist on the first level. If you process all files, and you enable the Other option Other on the first level does not only include all MP3 files without an artist tag, but also all other files in the database. Restricting the category to MP3 files solves this problem. |
Category Filter | This filter allows you to limit the files to consider for this category based on one or more other categories. See Category Filters above for more information. |
Language | Some metadata tags support multiple languages. If you want to use only data for one language as input for your data-driven category, you can choose that language here. IMatch lists only the languages in use in your database. |
Keep empty categories | This option is only available for the special @Keyword category. A data-driven category contains one child category for each unique value in the corresponding tag. If the tag value no longer exists, the corresponding category is removed as well when the data-driven category is refreshed. The @Keyword category has one child category for each keyword used by at least one file in your database. If you remove a keyword from all files, the corresponding category is also removed. This may not be what you expect, because you no longer will be able to add the keyword to files by assigning files to that category. You can just add the keyword to a file in the Keyword Panel and the category will re-appear. But it is often easier to keep empty child categories of @Keywords around. This option allows you to control that. When you toggle auto grouping on and off, this option can cause duplicate child categories. In this case, temporarily disable this option, refresh the category, then re-enable the option. |
| Formatting | |
Data Type | Usually the Automatic setting is best. IMatch uses the metabase to determine the data type of a tag and perform the proper formatting to convert it into a category name. Under some conditions you may want to force IMatch to treat a value as Text, Integer or Real data type. See also Numeric Ranges below. |
Use RAW value | By default, this setting is set to 'No'. In this case IMatch uses the formatted metadata value as returned by ExifTool. This is the correct setting for most tags. For some special purposes, and for tags which have a RAW value, you can set this option to 'Yes'. IMatch then uses the RAW value as contained in the file, without the additional formatting or mapping provided by ExifTool. Values like EXIF orientation or shutter speed are numerical values. The formatted values like "top-left" or "1/300" are calculated and provided by ExifTool. A formatted shutter speed of "1/125" has a RAW value of 0.008, for example. It sometimes may be useful to use the RAW values directly. If you enable this, you should set Data Type to Text in to avoid any additional formatting and to keep the RAW value 'as-is'. |
Trim | If you enable this option, IMatch removes blanks (spaces) and tab characters from the beginning and end of each value. |
| Character Mapping | If this is enabled, IMatch maps characters containing diacritics to their base characters. For example: 'hôtel' is mapped to 'hotel' , 'canapé' to 'canape' and 'educación' to 'educacion'If you have data with variant spellings for the same word, this makes it possible to fold all files into on category. Instead of one category for hôtel and another one for hotel, you now can have only one category for both terms. |
Use 'Other' element | If you work with multi-level data-driven categories, IMatch can generate so-called 'Other' categories to collect files with missing values. In our Make and Model example, you may have images without values in the Make tag. Not all cameras write this tag or the metadata may have been stripped from the file. If your database has 1000 files, only 700 may have information in the Make tag. So, on the Make level you will see only 700 files, split into categories named like "Nikon", "Canon", "Hasselblad" etc.. The remaining 300 files are not accounted for because they don't have data in the Make tag. If you enable the "Other" option, IMatch creates an additional category named "Other" which holds the missing 300 files without Make metadata. The name of this 'Other' category can be set with the option explained below. You may also run into this in multi-level data-driven categories. If you have Make on Level 1 and Model on Level 2, there may be files without a Model on level 2. Enabling Other for this level will include these files as well. |
Name for 'Other' | This property allows you to set the name IMatch uses for the 'Other' category. In our example above you could change this from the generic 'Other' to something with more meaning, e.g. "Images without Make info". If the name you choose here is part of the actual data, IMatch will take care that the name is unique by adding a number. |
Part of Value | If you want to use only a part of the value found in the database, enable this option and use Start and Length to specify the first character to use and the number of characters to use from each value. |
Start and Length | Two numeric values, separated with a comma. The first number is the index of the first character to use (starting at 1) and the second number specifies the number of characters to use. Set this to 0 to indicate "all remaining characters". Example 1,5 Start with the first character and use up to 5 characters of each value. Beach => Beach Motorway => Motor Vacation => Vacat 6,0 Start with the 6th character and use all remaining characters. _DSC_20100923 => 20100923 Motorway => way |
| Unify | |
Unify Spelling | If you want to unify the spelling of the data, use one of the options offered by this property. You can change all values to lower-case, upper-case or first letter upper-case. |
Word Boundaries | If you choose the option first letter upper-case, this property controls how IMatch detects word boundaries. Usually this is a space character, sometimes a tab character. Sometimes even a carriage return and linefeed - depending on the type of data you work with. To use multiple word boundary characters, separate them with ; In order to specify "non-printable" characters, IMatch supports some special keywords for this property: {tab} for tabulator character (0x9hex) {cr} for carriage return (0x13hex) {lf} for line feed (0x10hex) Example {tab}; ;-;{lf} |
| Add Auto-group | |
Enabled | Enable this option if you want to include an automatic grouping level in your data-driven category. Usually this option is used when you have only one level in your category and this level has hundreds or even thousands of values. If auto-grouping is enabled, IMatch uses a part of the value (specified by Start and Length below) to add another level above the level created using the data from the database. Example You want to create a data-driven category for keywords (XMP dc:subject tag). Since you have used hundreds of different keywords in your database, you want to group them by the first character for better handling. You enable auto-grouping and use a start and length value of 1,1. The output produced by IMatch then looks like this: Your Data-driven Category |-A | |-Above | |-Active |-B | |-Baby | |-Banana ... |-Z | |-Zoom The level above the actual keyword categories is automatically added by IMatch. Using the first character of each keyword, IMatch creates the categories "A", "B", ... "Z" etc. and below that creates the categories for each keyword starting with that letter. Adding such an extra level is a great help to further structure data-driven categories with hundreds or even thousands of child-categories. |
Start and Length | Specify the index of the start character (use 1 for the first character) and the number of characters to use for the autogroup. A good value is usually 1,1 because it limits the number of categories in the autogroup to about 25. But you can also use something like 1,2 or even 1,3 to autogroup by the first two or three characters in each value. Use Preview to try different combinations. You can close the Preview dialog box even when IMatch is still retrieving data. |
| Value Splitting | |
Enabled | Enable this option if the values contain more than one "element". This option instructs IMatch to split the source value into multiple values using a given separator character. The actual child categories are then created from these multiple values. Example The keywords in your images are written in multiple languages, and you have used a comma to separate them: Beach, Strand Mountain, Berg Female, Weiblich This or similar schemes is often used with IPTC because IPTC has no support for multiple languages. If you enable the value splitting and set the comma (,) as the separator, IMatch will split the above values into Beach Strand Mountain and create the child categories from these values. A file with the keyword "Beach, Strand" will be assigned to both the "Beach" and the "Strand" category. Repeatable ValuesAnother use for value splitting are values containing lists of elements, e.g. variables like {File.Persons.Label}:Tom;Paula;Frank;Susan Variables with repeatable values return the values separated with a semicolon Because the semicolon is used to separate multiple splitting characters, it must be escaped with |
Separators | Enter the separator used in your values. Separate multiple separators with a semicolon (;). If you have used ; as the separator in your data, enter ~; to indicate that. |
| Hierarchy | |
Detect Hierarchies | Enable this option if the metadata values contain hierarchical information and you want to use this to create additional levels in your categories. For example, if you have used the IMatch 3 script that writes IMatch categories into IPTC keywords, the metadata in your files contains entries like: Location.Beach.Daytona Location.Beach Vehicle.Car The script writes the full path of each category into the IPTC data and separates the levels with a dot ("dot-notation"). If you use Adobe Lightroom or Adobe Bridge in your workflow, your XMP metadata may contain a proprietary Adobe namespace with (among other data) a dc:hierarchicalKeywords metadata tag. This tag contains the hierarchical tags you have used in these products. These entries look similar to this: SUBJECT|Location|Beach|Daytona SUBJECT|Location|Beach SUBJECT|Transport|Car The full hierarchy of each tag is included in the entries, using | as the separator. Use the Preview... button in the Data-driven Category Editor to see what your files contain and which separator was used. IMatch allows you to use such hierarchical information when you create a data-driven category. IMatch will automatically re-create the hierarchy contained in metadata values, producing as many levels as needed under the data-driven category.The above examples will produce IMatch category trees like this: [Your Data-driven Category]
|-Location
|-Beach
|-Daytonaor for the Adobe dc:hierarchicalKeywords example: [Your Data-driven Category]
|-SUBJECT
|-Location
|-Beach
|-Daytona
|-Transport
|-CarThere are other schemas used by other software on the market to somehow "include" hierarchical keywords or tags in files. Most of these schemas can be handled easily with the hierarchy detection implemented in IMatch. Usually you don't need to create your own categories for hierarchical keywords. This is handled automatically by IMatch via the special @Keywords category. |
Separators | Enter the separator used in the values to separate levels in the hierarchy. Use ; to separate multiple separators. |
| Replace and Filter | |
| The Replace and Filter features allow you to clean up the values found in the database and limit the data-driven category to values matching a pattern or numerical range. In addition you can perform replacements to exchange parts of values or entire values, e.g. to remove unwanted characters from the input values or to correct misspellings. Both the Filter and Replace features rely on regular expressions. See Regular Expressions for detailed information. | |
Replace Mask | This mask allows you to replace text with other text. Both the source pattern and the replacement text are specified using a regular expression. Examples Bech,Beachreplaces all occurrences of "Bech" with "Beach". Ideal to correct typos in the metadata.You can also use a mask to shorten values before creating categories from it. For example: ^Central Processing Unit,CPUThis mask replaces all occurrences of "Central Processing Unit" at the start of a value with "CPU".You can also process multiple replacements masks. Just separate them with a ; If a ; is part of your mask, use ~; instead. .,-;^_DSC, This mask has two parts. The first part replaces all occurrences of "." with "-". The second part replaces all occurrences of "_DSC" with nothing. If your values contain digital camera file names, this is a great mask to clean them up. It is important that you don't add unwanted blanks (spaces) before or after the ; because these will be considered part of the mask. Just add the ; to separate the masks, without any blanks. To replace a string with nothing, use an empty replacement: _DSC,replaces all occurrences of _DSC with an empty string, so "_DSC00001.RAW" will become "00001.RAW". |
Case-sensitive | This property controls whether the replacements are case-sensitive. |
Filter Pattern | With a filter pattern you can restrict the input values to values matching the filter pattern. This allows you to control which values will be included in your data-driven category. Examples Nikon;CanonThis mask lets only values pass that contain the text "Nikon" or "Canon".^Arch.*This mask filters out all values not starting with "Arch". |
Case-sensitive | This property controls whether the filters are case-sensitive. |
Invert Filter | Set this to Yes to invert the result of the Filter Pattern. Only values not matching the Filter Pattern will be used to produce the data-driven category. |
Numeric Ranges | If you force the data type for the values to a numeric value (see Data Type above) you can specify one or more numerical ranges to include only certain values. The format is: lower,upper. You can specify multiple ranges using ; as a separator.1,10Let only values pass that are in the range 1 to 10. -20,-10Filters out all values below -20 or above -10. 1,100;400,1000Filters out all values not between 1 and 100 or 400 to 1000. |
Invert Ranges | Set this option to Yes to revert the numeric range. Only values that do not match the numeric range specified above will pass the filter. |
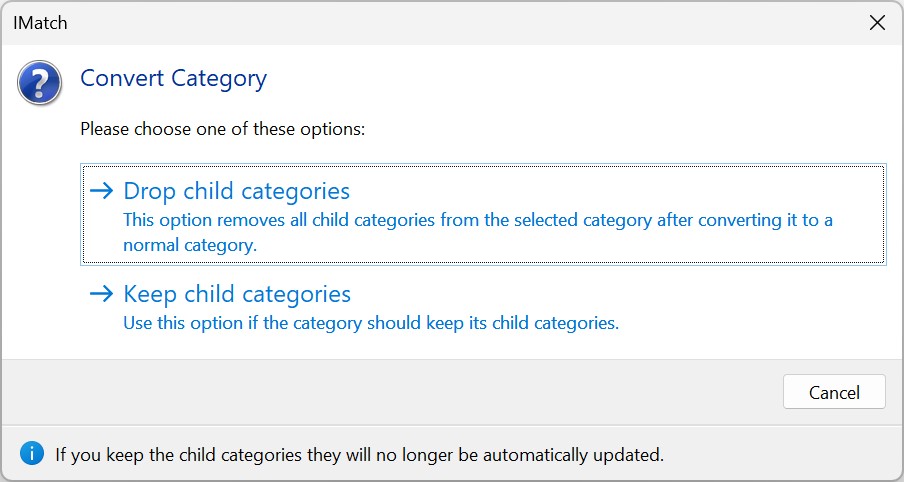
You can convert a data-driven category into a normal category using the Convert to normal category command available in the Advanced context menu. This command brings up a dialog box where you can choose how convert the category: