Enter the category formula directly into the property,
or click the ... button to open the Category Formula Editor.
Formulas are one of the unique features that make IMatch categories so powerful and flexible.
Formulas are one of the unique features that make IMatch categories so powerful and flexible.
Formulas allow you to combine categories via Boolean operators (AND, OR, NOT) and to access contents of folders, collections, events, etc. dynamically.
Usually you manually assign files to categories directly via one of the methods described under the topic Categories. Once the files have been assigned, they stay in the category until you un-assign them or you remove the files from the database.
But there is more to categories. Using category formulas enables you to create categories dynamically containing files from one or more other categories or collections. You can fill categories with files having certain metadata values, e.g., all files with a specific Rating or Label. All this can be done by setting a formula for a category.
You can add a formula to every 'normal' category. You cannot add formulas to system categories like @Keywords or data-driven categories.
Start by adding a new category somewhere and then right-click the category and select the Edit Formula... command from the context menu.
This opens the Category Formula Editor that allows you to input and edit your formula.
You can also click into the Formula field in the Properties Panel below the category tree to start editing your formula.
OK, so how does all this formula stuff work? This is not like taking that dreaded math class again. It's all pretty simple, really.
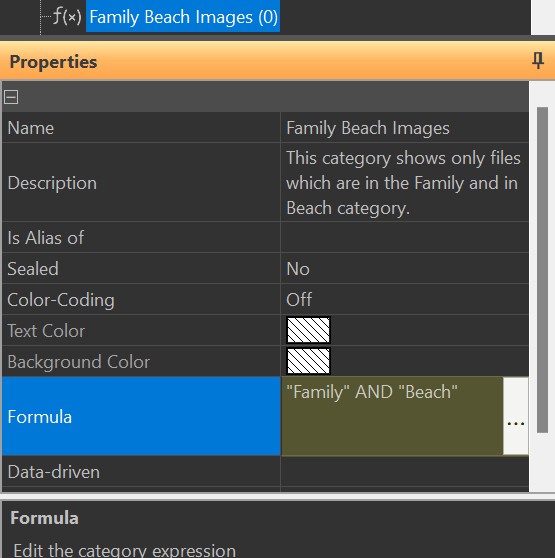
Consider that you have a category named "Beach" that contains all images taken at the beach. And you also have a category named "Family" which holds all your family photos. You have manually assigned files to these categories.
If you now want to see all images of your family at the beach, how can you achieve this? You would have to do something like "Show me all images that are in the category Beach and in the category Family". This is where category formulas come into play.
A category formula is plain text, entered either directly in the Formula Properties Panel in the Category View or via the Category Formula Editor.
Enter the category formula directly into the property,
or click the ... button to open the Category Formula Editor.
A category formula to answer the question above looks like this:
"Family" AND "Beach"
This formula tells IMatch to combine the contents of the "Family" category with the contents of the "Beach" category using the Boolean operator AND. The AND operator combines the two categories in a way that only files are returned that are in both categories: "Files in Family and in Beach".
When you reverse the order of the categories in the formula, the result is the same:
"Beach" AND "Family"
Category names must be enclosed in " (quotes) when you use them in formulas: Family AND Beach "Family" AND "Beach"
Boolean operators must be uppercase: AND, OR, NOT.
If you change the formula to use the OR operator instead of AND:
"Family" OR "Beach"
you instead get the files from both the "Beach" and the "Family" category combined: "Files that are in Family or in Beach".
If a file is in both categories, it is returned only once.
When you select multiple categories in the Category View, they are combined via OR.
The next formula uses the Boolean NOT operator to exclude all images in the "Family" category (return files that are in "Beach" but not in "Family").
"Beach" NOT "Family"
Not all that difficult, right? Another one:
"Family" NOT "Aunt Anne"
This formula returns all images assigned to the "Family" category, except images assigned to the "Aunt Anne" category. Use this if you don't want to see Auntie Anne's pictures when you look at your family photos.
You should seal a category when you set a formula.
It usually makes no sense to mix manually assigned files with the results of a formula. The results of such a mixed category may be confusing so it is better to prevent manual assignments by setting the Sealed property to Yes.
Usually you will use a category hierarchy in your database, with multiple levels or categories. In order to fully describe a category, you have to use a qualified name. A qualified category name (or path) includes all levels in the category name, starting at the top-level and down to the actual category you want to specify. The @All category is not included in qualified category names.
@All
|-- Location
|-- Beach
|-- Daytona
In this hierarchy, the Daytona category is on the 4th level. The fully qualified name is thus "Location|Beach|Daytona" (You don't include the @All category in a fully qualified name). Levels are separated with a pipe symbol: |
Previous IMatch versions used a dot . to separate levels. IMatch and later use | instead to free the dot to be used as part of category names.
This name uniquely identifies this specific Daytona category. Other categories with the name Daytona somewhere else in the category hierarchy (under a different parent category) will have a different qualified name.
You can combine any number of expressions into one formula. Consider the following expression:
"Beach" OR "Mountain" OR "City" OR "Sea"
This formula returns all files assigned to at least one of the "Beach", "Mountain", "City" or "Sea" categories.
IMatch allows the use of ( and ) parentheses to indicate operator precedence. IMatch by default evaluates operators from left to right:
"Beach" OR "Mountain" AND "Lisa" OR "John"
Here, IMatch first combines "Beach" with "Mountain" via OR. Then it combines the result of that with "Lisa" via AND. This removes (!) all images from the result that are not contained in the category "Lisa". Finally it combines the result of that via OR with the category "John".
The result of this formula may not be what you expect!
Because the result will contain only images with Lisa at the Beach or in the Mountains, and all other images with John. The problem is that the "AND Lisa" part is evaluated before the "OR John" part because IMatch processes formulas from left to right:
To make clear what you really mean, use parentheses:
("Beach" OR "Mountain") AND ("Lisa" OR "John")In this formula, IMatch first combines "Beach" with "Mountain" via OR. This gives all files taken either at the Beach or in the Mountains. Next, IMatch combines the categories "Lisa" and "John" via OR. This returns all images containing either Lisa or John or both. Finally, IMatch combines these two intermediate results for the final result via AND: All images from the beach or mountains showing either Lisa, John or both.
If in doubt, use parentheses to exactly express what you mean.
Unless all your categories are direct children of the @All category (which is unlikely) you will have to use fully qualified paths in formulas. For a hierarchy like this
@All |--Location |-- Beach |-- Mountain ... |-- Person |-- Lisa |-- John ...
The formula would read:
("Location|Beach" OR "Location|Mountain") AND ("Person|Lisa" OR "Person|John")The @All category virtually represents all files in your database. It is the parent category of all categories in your database. You can use the @All category like any other category name in your formulas. Due to the special nature of @All, its uses are mostly limited to formulas like:
"@All" NOT "Beach"
This formula returns all files in the database, except files contained in the category "Beach". Or, to choose all photos except your commercial photos:
"@All" NOT "Projects|Commercial"
Since IMatch mirrors all hierarchical keywords in your database in the special @Keywords category hierarchy, you can use formulas to combine files having specific keywords in any way you want.
This can be really helpful, e.g. when you create categories for files having specific combinations of keywords, or for files having keyword A but not B.
In addition to using actual category names in your formulas, IMatch also supports a number of keywords and functions in formulas. The following table lists all predefined keywords and explains their usage. Using one of these functions can help you solve some tricky issues or to easily get the results you want.
You don't need to type all these function names by hand. Use the Category Builder and just point and click.
@All | The special @All category represents all files in your database. | ||||||||||||||||
@Unassigned | This keyword returns all files not directly assigned to a category. This keyword can be used only once, in one category, and this category must be a child of @All. | ||||||||||||||||
@Uncategorized | This category returns all files in the database not yet assigned to any category, either directly or via a formula or included in a data-driven category. Use this keyword to find all files not assigned to any category at all. A file which has at least one keyword will not show up in this category. It will show in @Unassigned. A file that is 'grabbed' by a data-driven category does not show up in this category. It will show in @Unassigned. A file which has been assigned to a category directly does not show up in this category. It will also not show in @Unassigned. When there are data-driven categories which need to be re-calculated, this category may temporarily return false results until all data-driven categories have been updated. | ||||||||||||||||
@Builder | This category returns the current result of the Category Builder. | ||||||||||||||||
@Category[] | In its most basic use, this function takes the fully qualified name of a category and returns all files contained in that category and its child categories. "@Category[@All|Location|Beach]"This formula, and the related formulas @CatDistinct and @CatNoRecurse work in one of two modes: 1. Starting with @All : @Category[@All|Location|Beach]When you expression begins with @All, IMatch considers every level specified individually. Every level can contain a regular expression, but the levels specify exactly where in your category hierarchy IMatch searches. 2. Expressions without @All : @Category[Location\|Beach]When your expression does not start with @All, the entire expression is considered as one regular expression. Since | has a special meaning in regular expressions, you have to escape it with \ in order to tell IMatch that you actually mean a category level. IMatch searches the entire category hierarchy for categories, or partial hierarchies, matching your expression. An expression which searches your entire category tree can take several seconds if you have many categories. Use expression of this type sparingly because you can create a performance problem by using these powerful yet slow expressions too often. It will all become clearer with a couple of examples. Examples
A note about Performance: | ||||||||||||||||
@CatNoRecurse[] | This keyword returns only the files contained in the given category, without files contained in child categories. It expects a regular a expression."@CatNoRecurse[@All|Location|Beach]"Using a full regular expression, starting with @All, is very important here. If you would just specify "@CatNoRecurse[Beach]" the regular expression would pick up any category containing Beach in it's name, which includes the child categories of Beach. And since you use @CatNoRecurse to explicityl exclude the child categories of Beach, you don't want this to happen. | ||||||||||||||||
@CatDistinct[] | This keyword returns only files exclusively contained in the given category. Files assigned to any other category are not included in the result. It expects a regular expression."@CatDistinct[@All|Location|Beach]" Restricting the Search Scope Sometimes you may want to restrict where this function looks for files. Consider the following hierarchy: ... |- Location |- Berlin |- London |- New York |- Persons |- Abby |- Jenny |- John |- Max If you want to find all files with only Jenny in it, but no other Person, using the @CatDistinct formula like this will not give you the expected results: "@CatDistinct[@All|Persons|Jenny]" if Jenny is assigned to at least another category. Since Jenny has been assigned to the "Location|London" category, it is no longer distinctively (exclusively) assigned to "Person|Jenny". The above formula thus returns an empty result! To overcome such situations, and to tell IMatch things like "Show me all files to which only Jenny is assigned under Persons", you can add a second argument to the formula. The second argument tells IMatch where to look for categories to determine if a file is distinct. "@CatDistinct[@All|Persons|Jenny;@All|Persons]"The red part that follows the ; tells IMatch which categories to consider when determining categories to which Jenny is exclusively assigned. In this example, the expression will return all files under @All|Persons to which only Jenny is assigned. Files assigned to either Max, Abby or John will be removed from the result. If Jenny is assigned to other categories outside @All|Persons this has no influence on the result. General Syntax: "@CatDistinct[Search Expression;Scope Expression]"Both expressions are regular expressions. | ||||||||||||||||
@Rating[] | This keyword returns all files with the given XMP Rating. Possible values for rating are:
"@Rating[1]" (all files with a rating of 1) "@Rating[-1]" (all rejected files) "@Rating[0]" (all files without a rating) "@Rating[4]" OR "@Rating[5]" Of course you can combine this function with other formulas. The following formula returns all files with a rating of 3 or better that are also in the category "Location.Beach". "Location|Beach" AND ("@Rating[3]" OR "@Rating[4]" OR "@Rating[5]")If you use this often, you may want to create a category named like "Rated 3 or better" using this formula: "@Rating[3]" OR "@Rating[4]" OR "@Rating[5]" and then combine this category with other categories as needed: "Location|Beach" AND "Rated 3 or better" | ||||||||||||||||
@Label[] | This keyword returns all files with the given XMP label. Usage: "@Label[Red]" "@Label[Review]" OR "@Label[Select]" | ||||||||||||||||
@Collection[] | This keyword returns all files in the given collection. Having the ability to use collections in category formulas opens up all kinds of interesting possibilities. Usage: "@Collection[Pins|Green]"This formula returns all files with a green pin. "@Collection[Pins|Red]" OR "@Collection[Pins|Green]" OR "@Collection[Pins|Blue]"This formula returns all files with at least one pin. "@Collection[Dots|Red]"This formula returns all files with a red dot. Note that Rating and Label can also be used with the @Collection keyword. | ||||||||||||||||
@Folder[] | This keyword returns all files in the given folder. The syntax for the folder specifier in the square brackets is: "@Folder[Fully qualified URN path<Media Label.Media Serial Number>]"The fully qualified path is a standard Windows folder path or UNC path. You must use the formal URN syntax: file://folder/.../folder with forward slashes between the individual folder names. Optionally the path URN is followed by the media label and media serial number wrapped in < and >. You should always include the media label and media serial number in @Folder or @RFolder functions, to be on the safe side when you work with removable media. If you work with removable media (CD, DVD, BD) a statement like "@Folder[r:\photos]" can mean different media and is not unique. Thankfully the Formula Editor dialog box fills in all this information for you automatically. You don't need to type all this by hand. Geez. | ||||||||||||||||
@RFolder[] | This keyword returns all files in the given folder, including files in sub-folders, recursively. The syntax for this function is the same as for @Folder[] above. Usage: "@RFolder[URN Path<Media Label.Media Serial Number>]" | ||||||||||||||||
@FolderRegExp[] | This function allows you to find folders by their name using a regular expression. The function returns the combined list of files for all folders matching the given regular expression. This makes it very easy to set up categories virtually containing files in all folders with a specific name. For example, if you store your print-ready files in folders named "print", you can combine all these files into a category using this function. As all formula-based categories, IMatch keeps the category up-to-date automatically. Only the files in the matching folders are included. If you also want to include files in their sub-folders, use @RFolderRegExp function instead. The following expression "@FolderRegExp[print]" finds all folders containing the word print, anywhere in the path. "@FolderRegExp[print$]" This expression finds all folders ending with the word print. IMatch always uses the fully qualified folder name to match the regular expression. Consider the following folder names: c:\images\printer\funny c:\images\2012\vacation\print If you specify "@FolderRegExp[print]" as your regular expression, all files from all four folders will be returned. To find only the highlighted folder, use "@FolderRegExp[print$]" to indicate that you are only interested in folder names ending with print. This excludes folders containing the word print somewhere in the middle, and also the sub-folders of the folder ending with print. If you want to find folder names containing print (or any other expression) somewhere in the middle, you can include a backslash in your regular expression, e.g. "@FolderRegExp[print\\]. Note that \ has a special meaning in regular expressions and that you have to double it as \\ to use it as a literal character. | ||||||||||||||||
@RFolderRegExp[] | This function is identical to @FolderRegExp but also includes the files in sub-folders of folders matching the given regular expression. | ||||||||||||||||
@FileRegExp[] | This function allows you to produce categories from files with certain file names. This is a very useful function if you encode information in your file names (e.g. location, workflow step, client code or color version) and you want to categorize your files based on this information. For example, if you want to put all files with the extension .jpg into one category, use a formula like this: "@FileRegExp[\.jpg$]" Or if you use certain codes in your file name to indicate source, colors or persons contained in the file, you can grab these files easily as well. For example, if you include _BW_ as part of the file name to indicate black and white photography, you can combine all these files into a category with the following simple formula: "@FileRegExp[_BW_]" Another often used method to include information in file names is to append a postfix like _lr to indicate a low-res version of a file, e.g. for website usage. To dynamically combine all these files into a category, use a formula similar to this: "@FileRegExp[_lr\..*$]" This regular expression finds all files ending with _lr, followed by a . and the extension. This formula has to evaluate the name of each file in your database. An alternative may be a data-driven category which also offers ways to filter the results and to produce a hierarchy. | ||||||||||||||||
@MetadataTag[] | This versatile function enables you to fill a category with all files having none, any or specific data in a metadata tag. It works similar to the metadata filter in the Filter Panel. General Syntax: Supported OperatorsThe following operators are supported: These operators are also supported by the @Variable[] and @Attribute[] formulas. hasvalue and novalueSyntax: [<tag key>,hasvalue {,rawvalue}] [<tag key>,novalue {,rawvalue}] These operators allow you to find files based on whether or not they have a value for the specified metadata tag. If the optional rawvalue option is specified, the search is performed on the raw tag value instead of the formatted value.This formula returns all files without a value in the XMP title tag: "@MetadataTag[title,novalue]"This formula returns all files with a non-empty XMP title. "@MetadataTag[title,hasvalue]"You can use all metadata tags supported by IMatch. Both the standard tag syntax and shortcodes are supported: "@MetadataTag[XMP::dc\title\Title\0,novalue]"This formula uses the rawvalue option to search the raw value of the GPS latitude:"@MetadataTag[gpslatitude,novalue,rawvalue]"For GPS coordinates, IMatch internally sets the raw value when you modify the coordinates in the Metadata Panel or the Map Panel. Only when the file is written back, ExifTool produces a formatted value from the RAW value that is then imported into the database. See Metadata Variables: Formatted and Raw for related information. regexp and notregexpSyntax: [<tag key>,regexp,<regular expression>] [<tag key>,notregexp,<regular expression>] Note: If the regular expression contains a comma , it must be escaped with ~ With these two operators you can find files which have a tag value matching the given matching or not matching the given regular expression. "@MetadataTag[title,regexp,beach]"Finds all files which have the word beach somewhere in the XMP title tag."@MetadataTag[title,regexp,^beach]"Finds all files with a title starting with the word beach."@MetadataTag[title,regexp,beach$]"Finds all files with a title ending with the word beach.This expression finds all files with the value True in the XMP Cropped field. The resulting category will show all cropped files: "@MetadataTag[cropped,regexp,^True]"More examples for regular expressions can be found in the Regular Expressions help topic. betweenSyntax: [<tag key>,between,<Lower>,<Upper>] The between operator allows you to find files with an value between two numbers. The tag value is converted to a floating point number and then compared to the lower and upper number. All numbers are rounded to 4 decimal places before the comparison is performed. This formula returns all files with an ISO value between 0 and 400, inclusive: "@MetadataTag[iso,between,0,400]" Larger than, smaller than, ... You can also use this operator to find files with values greater than or less than (or greater than or equal,...). For example, to find all files with a rating > 3; "@MetadataTag[rating,between,4,99]"This expression implements ISO value must be smaller than 200: "@MetadataTag[iso,between,0,199]" contains-any | ||||||||||||||||
@Variable[] | This very powerful formula allows you to categorize files based on variables. General Syntax: The variable and the Operator are mandatory. If other parameters are required depends on the operator. The formula evaluates the specified variable for each file in the database and then applies the operator to the result. If this produces a true value, the file is included. Except for the Set and Attribute name, this formula supports the same operators and parameters as the @MetadataTag formula described above: Example: @Variable[{File.MD.title},hasvalue]This formula assigns all files containing a person with a label containing the word Tom or Susan to the category.@Variable[{File.Persons.Label},contains-any,Tom;Susan]Using @Variable[] can help solving very tricky problems, but it comes at a price. | ||||||||||||||||
@Attribute[] | This formula allows you to work with data stored in IMatch Attributes. You can use this formula to organize and group your files based on Attribute values. This can be very helpful if you work with Attributes a lot. General Syntax: Except for the Set and Attribute name, this formula supports the same operators and parameters as the @MetadataTag formula described above. Example: "@Attribut[Notes.Text,contains,beach]"Returns all files where the Text Attribute in the Notes Set contains the word beach. | ||||||||||||||||
@YearsAgo[] | This formula returns all files created on the same day as today, but one, two or more years in the past. General Syntax: The number must be Example: "@YearsAgo[1]"Returns all files created on the same day, but one year ago. |
Although you can type the formula directly into the property grid below the category tree, it is often more convenient and safer to use the category formula editor.
Right-click the category for which you want to add or edit the formula and choose Edit Formula from the context menu.
If the Properties Panel is visible, you can also just click on the ... in the Formula row.
The formula editor is divided into two areas. On the left you see a list of all functions and operators plus controls that allow you to directly select folders, categories and collections. On the right side is the text editor where you enter the category formula.

When you click on one of the keywords or folders/categories/collections on the left, IMatch inserts the corresponding formula into the editor at the current cursor position. You should position the cursor at the spot where you want to insert the new element before you click on it.
The formula editor allows you to quickly build category formulas by just point and click. If needed you can edit the formula in the text editor by hand afterwards.
To verify the formula, click on the Test button. If there is an error with the formula, IMatch displays an error message with additional information.
If you are done, click OK to close the dialog box and return to the Properties Panel.
Linefeeds are ignored by the formula editor and the formula processor in IMatch. This allows you to break a formula into multiple lines for a better overview.
To insert a new line, press Ctrl+Enter.
When you create many formula-based categories and your database is fairly large, calculating these categories may take quite some time. The more complex your categories are and the more of them you have, the more computing and disk resources are needed to update the categories.
IMatch has to recalculate categories when something affecting their result changes. For example, when you modify metadata, rating, label, collections etc.
IMatch optimizes calculations internally, uses caching, multiple processor cores etc. But there are limits of what can be done. Updating a category that, for example, uses @MetadataTag[], requires IMatch to load the tag data for each file in the database in order to figure out which of the files belong into the category. That requires a lot of disk I/O. And that every time the category needs to be updated. This may 'max out' the disk containing the database for a long time (several seconds) and in turn all other features in IMatch which need the disk will slow down.
Categories are updated when they are visible somewhere, or when their counts (number of contained files) are required. If a category is visible in the Category View, the Category Panel or Category filter, it will have to be updated every time you change metadata in your database. Not a real problem with one or two slow categories, but it can become a performance issue when you have many of these categories or your database is very large.
In such cases it is a good idea to place the complex/expensive categories under a parent category and to set the property Direct Assignments Only of the parent category to Yes.
If you collapse the parent category, all the complex (and expensive to update) categories are hidden and their counts are not needed (that's because of the Direct Assignments Only property). This allows IMatch to delay updating these categories until their results are needed again.
The IMatch Standard Categories and IMatch Workflow Categories default categories use this trick.
The Performance Panel in the Dashboard lists categories which take a long time to update.